


In der heutigen dynamischen IT-Landschaft ist es unerlässlich, Anwendungen schnell und zuverlässig bereitzustellen, ohne den laufenden Betrieb zu unterbrechen. Eine bewährte Methode, um dies zu erreichen, ist das Blue-Green Deployment. Dieses Verfahren ermöglicht es, neue Versionen von Software nahtlos einzuführen und gleichzeitig das Risiko von Ausfallzeiten und Fehlern zu minimieren.
In diesem Blogpost werden wir das Konzept des Blue-Green Deployments am Server genauer unter die Lupe nehmen. Wir erklären, wie diese Methode funktioniert, welche Vorteile sie bietet und wie sie in der Praxis umgesetzt werden kann. Egal ob du ein erfahrener DevOps-Ingenieur oder ein IT-Neuling bist, diese Einführung gibt dir das notwendige Rüstzeug, um Blue-Green Deployment erfolgreich in deiner Umgebung zu implementieren.
Lass uns gemeinsam die Schritte durchgehen, die erforderlich sind, um einen reibungslosen und effizienten Deployment-Prozess zu gestalten und die Zuverlässigkeit deiner Server-Infrastruktur zu erhöhen.
Die Theorie – Was ist Blue-Green Deployment und wie funktioniert es?
Blue-Green Deployment ist eine moderne Methode, die in der Softwareentwicklung und im IT-Betrieb eingesetzt wird, um neue Versionen von Anwendungen sicher und effizient bereitzustellen. Dabei wird die Produktionsumgebung in zwei nahezu identische Umgebungen aufgeteilt, die als “Blue” und “Green” bezeichnet werden. Diese Methode ermöglicht es, neue Versionen von Software zu implementieren, ohne den laufenden Betrieb zu unterbrechen und mit minimalem Risiko von Ausfallzeiten.
Funktionsweise von Blue-Green Deployment
- Vorbereitung der Green-Umgebung: Die aktuelle Produktionsumgebung (Blue) läuft und bedient die Benutzer. Eine neue Version der Software wird in einer separaten Umgebung (Green) bereitgestellt. Diese Umgebung ist eine exakte Kopie der Blue-Umgebung, aber ohne aktiven Benutzerverkehr.
- Testen der Green-Umgebung: In der Green-Umgebung wird die neue Version gründlich getestet. Dadurch wird sichergestellt, dass alle Funktionen wie erwartet arbeiten und keine neuen Fehler eingeführt wurden.
- Umschalten des Verkehrs: Sobald die Green-Umgebung erfolgreich getestet wurde, wird der Benutzerverkehr von der Blue-Umgebung zur Green-Umgebung umgeleitet. Dies kann durch DNS-Änderungen oder durch Load Balancer-Konfigurationen erfolgen.
- Überwachung und Rollback: Nach dem Umschalten wird die neue Version in der Green-Umgebung überwacht, um sicherzustellen, dass sie stabil und fehlerfrei läuft. Sollte ein schwerwiegender Fehler auftreten, kann der Benutzerverkehr schnell wieder auf die Blue-Umgebung zurückgeschaltet werden.
Was sind die Vorteile von Blue-Green Deployment?
- Minimierung von Ausfallzeiten: Da das Umschalten zwischen den Umgebungen nahezu sofort erfolgt, werden Ausfallzeiten auf ein Minimum reduziert. Benutzer bemerken in der Regel keine Unterbrechung des Dienstes.
- Schneller Rollback: Treten Probleme mit der neuen Version auf, kann der Verkehr schnell wieder auf die vorherige (Blue) Umgebung umgeleitet werden. Dadurch werden die Auswirkungen auf die Benutzer minimiert.
- Erhöhte Sicherheit: Neue Versionen werden in einer separaten Umgebung getestet, bevor sie live geschaltet werden. Dadurch können Fehler und Sicherheitslücken frühzeitig erkannt und behoben werden, ohne die Produktionsumgebung zu gefährden.
- Kontinuierliche Verbesserungen: Blue-Green Deployment ermöglicht es, regelmäßig neue Versionen und Updates bereitzustellen, ohne die Benutzererfahrung zu beeinträchtigen. Dies fördert eine Kultur der kontinuierlichen Verbesserung und Innovation.
- Einfachere Wartung und Updates: Die Trennung der Umgebungen erleichtert die Wartung und das Einspielen von Updates. Neue Features können in der Green-Umgebung entwickelt und getestet werden, bevor sie in die Produktion gehen.
Die Praxis – Ein Beispiel am Home-Server und Spielwiese
Als ersten Schritt stelle ich zwei Rechner auf, installiere das Linux meiner Wahl und schließe dies Beiden ans Netzwerk an.
Hardware
Meine Hardware sieht wie folgt aus, hier hat man auch einiges an Spielraum zu Abweichungen. Gewisse Grenzen gibt es, ich würde zB nicht 32-bit und 64-bit “mischen”. Die Software-Kompatibilität ist nämlich zwischen den beiden Systemen nicht garantiert. Ebenfalls müssen natürlich die Mindestanforderungen aller gewünschten Services von beiden Systemen erfüllt werden.
Blue
Mainboard: Lenovo 5JKT54AUS
CPU: Intel(R) Core(TM) i5 CPU 650 @ 3.20GHz
RAM: 8 GB
DISKS: ST3320620AS - 320 GB, ST8000AS0002-1NA - 8TBGreen
Mainboard: Asus P8Z77-V PRO
CPU: Intel(R) Core(TM) i7-3770K CPU @ 3.50GHz
RAM: 16 GB
DISKS: Samsung SSD 860 - 250 GB, WDC WD10EFRX-68J - 1TBHier sieht man auch wunderbar, dass die Systeme nicht ident sein müssen, was man zur Verfügung stehen hat, kann man verwenden. An meinem Setup werde stört mich eine Sache die ich unbedingt nachbessern muss. Ich habe immer eine System- und eine Datenplatte pro Server. Beim Backup-System (Green) habe ich zu wenig Festplattenspeicher an der Datenplatte, sodass ich nicht die selbst geschossenen Fotos synchronisieren kann, da der Speicher dafür aktuell schon nur sehr knapp ausreicht.
Software
Nun zur Software, hier ist es sehr viel wichtiger, dass diese möglichst ident ist. Natürlich gibt es auch hier Spielraum, jedoch wesentlich weniger als bei der Hardware, und je identischer die Software und deren Konfiguration, desto weniger Probleme können meiner Erfahrung nach auftreten.
Ich empfehle bei der Software auf die bevorzugte Linux Distribution zu setzen, und dort nach Setup-Guides aufzusetzen.
Wenn man das System aufsetzt, dokumentiert man diese Schritte am besten gleich mit. Damit ist man im Fall des Falles (zB: Hardwareausfall der Systemplatte) gerüstet und kann rasch eingreifen.
Das ist auch ein genereller Ratschlag von mir: Alles an den beiden Systemen sollte an einer zentralen Stelle so exakt wie notwendig mit dokumentiert sein.
Da mittlerweile alle meine Services innerhalb von Docker-Containern laufen, ist in meinem Fall kein großes Setup notwendig. Diese habe ich auch mittels compose so angelegt, dass ein neuinitialisieren jederzeit problemlos möglich ist. Ist dies jedoch nicht der Fall, empfehle ich, unbedingt wie wesentlichen Teile sauber zu dokumentieren.
Läuft die Software auf beiden Systemen, hat man erst einmal einen Zustand, den man als Synchronisiert bezeichnen kann. Nun legen wir eines der Systeme als führendes System fest und passen das Routing entsprechend an. Damit werden alle Anfragen von außen von diesem System (Blue) beantwortet.
Snychronisation der Daten
Dieser Zustand hält jedoch nur so lange an, so lange keine Änderungen vorgenommen werden, was natürlich völlig unrealistisch ist.
Alleine, wenn ich ein neues Foto am Handy mache, einen Blogpost erstelle, usw. – verändere ich damit den Datenstand auf dem aktuell führenden System.
Wie schaffen wir das?
Im ersten Schritt identifiziere ich, was alles zwischen den Systemen synchronisiert werden muss. In meinem Fall sind das alle Systemeinstellungen (/etc), Docker Container Daten (beliebiges_Container_Verzeichnis/data), meine Fotos (/media/fotos), Dokumente (/media/documents).
Um dies einfach und sicher zu bewerkstelligen verwende ich die Software Syncthing. Eine genaue Beschreibung würde hier den Rahmen sprengen, vielleicht kommt einmal ein eigener Artikel der sich dieses Themas annimmt.
Worauf ist noch zu achten?
Ich beim Setup eine Kleinigkeit unerwähnt gelassen. Die Systeme weisen kleine Unterschiede in ihrer Konfiguration auf. Das beginnt beim Hostnamen und zieht sich über die MOTD (Message Of The Day) bis hin zu unterschiedlichen Verzeichnissen (für zB die Docker Services / Container).
Einerseits müssen Anpassungen bei diesen Dingen ebenfalls synchronisiert werden, andererseits dürfen diese nicht mit Werten vom anderen System überschrieben werden.
Ich habe mir hierfür eine recht simple Lösung überlegt. Ich habe ein Verzeichnis für alle meine Shell-Skripte, welches ich immer auf jedes System aus dem GIT Repository auschecke und dort dann in den Pfad hinzufüge.
Und überall, wo ich Speziallogik bzw. -einstellungen nur für ein bestimmtes System haben möchte, nutze ich den Hostnamen als Erweiterung.
Nehmen wir zum Beispiel die MOTDs:
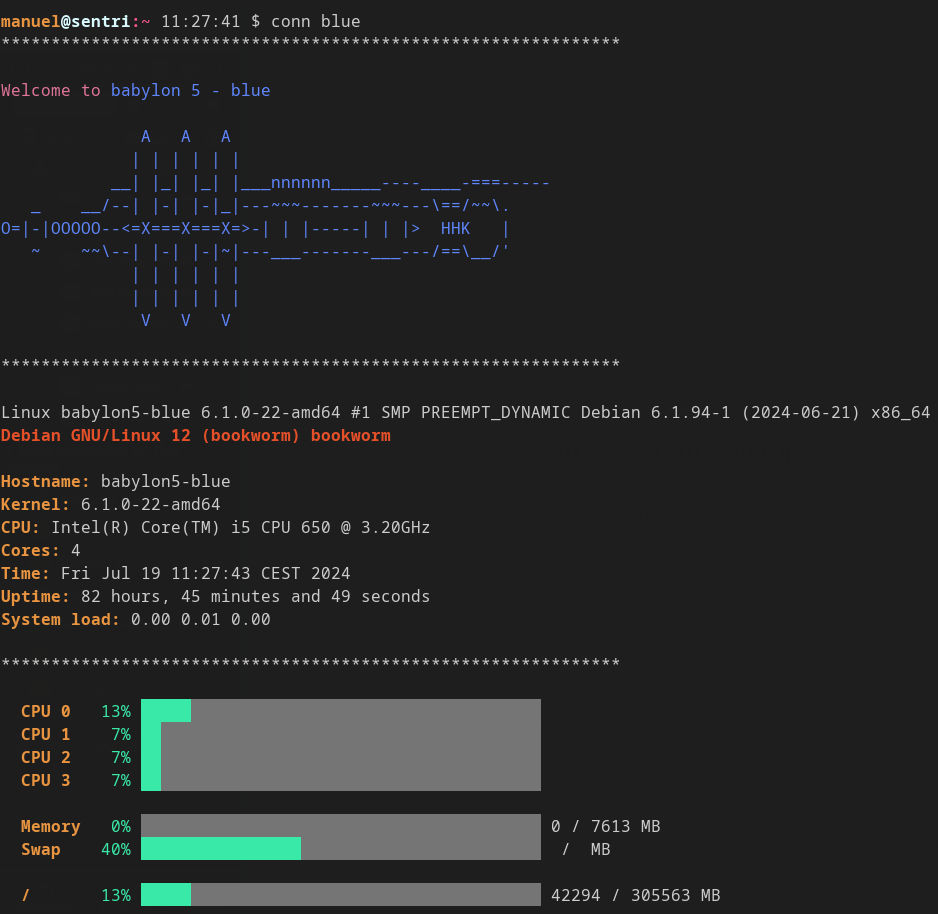
Blue
Green
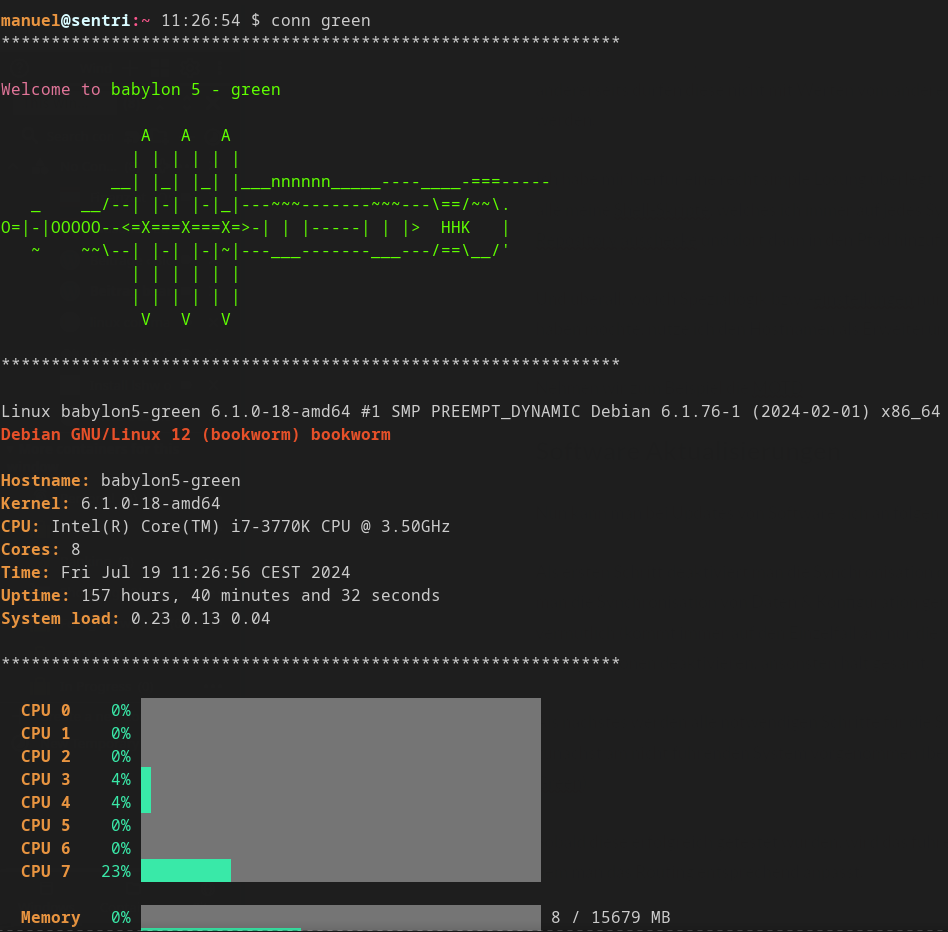
Auf den Screenshots ist gut ersichtlich, dass jeder Server eine eindeutige MOTD ausgibt. Gleich verhält es sich mit dem Eingabe-Prompt, da ich auf einen Blick sehen möchte, auf welchem System ich mich befinde.
Ich habe ein Verzeichnis ~/bin/motd/ in welchem ich die MOTDs für alle Systeme pflegen kann, dort gibt es dann Unterverzeichnisse wie motd-babylon5-green oder motd-babylon5-blue. Diese werden dann für das jeweilige System herangezogen.
Analog dazu mache ich es bei den Docker-Containern, wo notwendig (zB: bei Syncthing).
Damit können wir uns dem nächsten Thema widmen, ein System bzw. die Services sind ja nicht statisch und brauchen daher regelmäßig eingespielte Updates.
Software Updates
Nun kann man bei Updates von Software sich an folgendes Vorgehen halten.
Als ersten Schritt deaktiviert man die Synchronisation der beiden Systeme. Ist man die Synchronisation von Daten & Konfiguration getrennt, kann man vermutlich (kommt immer auf den Einzelfall an) nur die Synchronisation der Konfigurationen deaktivieren, ansonsten halt gesamt.
Idealerweise hält man auch seine Redakteure / User an, während des Aktualisierungs-Prozesses keine Änderungen am System vorzunehmen, da dies beim erneuten Einschalten der Synchronisation Probleme verursachen kann.
Als nächstes werden alle notwendigen Schritte für die Software-Aktualisierung zunächst am nicht führenden System (Green) vorgenommen.
Nun teste ich die betroffenen Software-Komponenten intensiv. Sobald die Tests erfolgreich abgeschlossen sind, wechsle ich das führende System von Blue zu Green, in dem ich das Routing entsprechend anpasse.
Meine Empfehlung wäre entweder danach ein paar Tage zu warten um sicher zu stellen, dass nicht doch noch Probleme auftreten. Alternativ kann man ein Backup (inkl testweiser Wiederherstellung) durchzuführen, bevor man das zweite System ebenfalls aktualisiert.
Fazit
Blue-Green Deployment ist eine leistungsstarke Methode, um Softwareänderungen sicher und effizient in die Produktionsumgebung zu integrieren. Durch die Minimierung von Ausfallzeiten, die Möglichkeit eines schnellen Rollbacks und die Förderung kontinuierlicher Verbesserungen trägt es wesentlich zur Stabilität und Zuverlässigkeit moderner IT-Infrastrukturen bei. Diese Methode ist besonders nützlich in Umgebungen, in denen Hochverfügbarkeit und kontinuierliche Bereitstellung entscheidend sind.
Wir haben uns die Theorie von Blue-Green-Setups angesehen, wie man von der Theorie zu einer Umsetzung in der Praxis kommt und auf was man achten sollte.
Manche Themen konnte ich hier nur streifen, wie zB die Synchronisation mit Syncthing, das (möglichst) automatisierte Setup eines Servers, wie man unterschiedliche Konfigurationen pflegt und wahrscheinlich noch weitere.
Falls ich zu einem der Themen einen ausführlicheren Blogbeitrag erstelle, werde ich diesen hier selbstverständlich verlinken. Bei Interesse an einer tiefergehenden Diskussion freue ich mich über Ihre Kontaktaufnahme.